Overview of fuzz testing software
Learn about fuzzing and it's usefulness in automated testing
History
The term "fuzz" was introduced in an article by Barton P. Miller, in which he randomly generated inputs to test Unix utilities. In the days before the widespread Internet, uncorrelated input was thought of more in terms of stability. Random input testing was known but was not perceived in security context.
With the advent of the Internet, software began to work more frequently with external data, thereby began to face attacks. Fuzzing quickly became a very relevant tool for detecting certain types of vulnerabilities that reduced the overall reliability and security of software.
Let's explore fuzzing.
The vulnerabilities that fuzzing reveals
Most of the bugs uncovered by fuzzing are related to input control. The tested programs lacked coverage of some extreme values of the inputs. For example, large numeric values, long inputs, or inputs that do not adhere to the format in some other way.
These implementation errors, in combination with malicious input, may have consequences of varying severity. The consequence can be reduced availability due to crashing the application, slow processing of inputs (algorithmic blowup), overflowing memory (e.g., zip bombs), or endless loops. However, the impact can be more severe, for example, with the possibility of RCE, SQL Injection attacks, XSS, or path traversal. Passwords and cryptographic keys can be stolen as a result.
It is also important to note that fuzzing exposes bugs in implementations in most programming languages and is not only relevant to memory errors in programs written in languages such as C/C++.
Fuzz target
The fuzz target is the part of the interface that is subject to fuzzing. It can be the entire program or an isolated part of it, such as a parser module in a compiler.
The first step in fuzzing is to identify targets suitable for this testing. This is where Attack Surface Analysis comes in. Attack surface is a list of points through which an unauthorized user can interact with the system. The APIs that are most interesting from a security perspective tend to be those that cross the trust boundary. This includes input from the user or input from the network.
Fuzzing can be viewed as a search algorithm, and as such, it needs many iterations. Therefore, the API under test should be as narrow as possible. By splitting the API and testing parts of it separately, we can achieve better results. For the same reason, it is essential to minimize the duration of evaluating a single input. Some simple speedups include eliminating logging, compiling with optimizations, and reducing work with files.
In fuzzing, deterministic behavior is important for repeatability. If the application uses a random number generator, it is desirable that it be replaced by a replicable variant for testing. For such modifications before testing, conditional translation is appropriate.
Fuzzing harness
In the case of testing a library or an isolated program component, the entry point for fuzzing must be created. Such an entry point is called a harness. Practically speaking, it is a function that can be thought of as a main in most programming languages. The harness argument is typically an array of bytes containing the data generated by the fuzzer. In its body, it executes any necessary initialization of the program's state and the actual API call with the passed data.
The harness also helps split the generated input into multiple parts. An example might be fuzzing a library for regular expressions. We need to split the input into three parts: the regular expression (RV), the flags to compile the RV, and the string to which the RV is applied.
Typically, a harness is universal and can be shared across compatible fuzzers.
Fuzzing engine
A fuzzing engine, or a fuzzer, is a tool that generates inputs and calls a fuzz target with them. There are many tools to do this. Some are simple to deploy, but there are more powerful fuzzers available that are more difficult to configure. It is possible to implement a custom fuzzer if no publicly available fuzzer meets the specific requirements of the project.
The task of the fuzzer is to generate inputs that detect as many errors as possible. Effective inputs are usually valid enough to not be rejected by basic checks, but somehow non-standard to cause unexpected behavior.
Fuzzing can be divided according to the way the inputs are generated into:
- Random fuzzing,
- template fuzzing,
- mutation fuzzing,
- evolutionary fuzzing.
Random fuzzing is sometimes called dumb fuzzing. A sequence of bytes is sent to the input in an unsystematic, random fashion. Its advantage is ease of deployment, but it won't be surprising to learn that without knowing the correct structure of the input and the inability to provide feedback, other methods will be more effective in detecting bugs.
Template-based or generational fuzzing uses a given set of correct and incorrect inputs in the form of templates or grammars. Specifically, inputs are then generated from the templates. Creating templates is more laborious, but for common formats such as HTTP or JSON, you can find a pre-made template.
Due to the ignorance of the internal structure of the program, random and templated fuzzing is also called "black box fuzzing."
Mutation-based fuzzer has access to the source code of the application and tries to maximize code coverage (the number of unique lines executed during testing). Fuzzers in this category are therefore called coverage-guided or graybox fuzzers. They are more suited for smaller components under test.
Each input that covers a new line of code is considered interesting and is added to a set of inputs called a corpus. Mutation fuzzing generates new inputs by modifying inputs from the corpus. The corpus is preserved across fuzzing sessions and may even be part of a code repository. Before first fuzzing, several inputs are created manually (the seed corpus). The efficiency of fuzzing depends crucially on the quality of the corpus.
As the number of inputs in the corpus increases, the redundancy increases. Fuzzing tools can typically reduce the corpus to a minimal set such that its code coverage remains the same. Figure 1 illustrates the flow of mutation fuzzing.
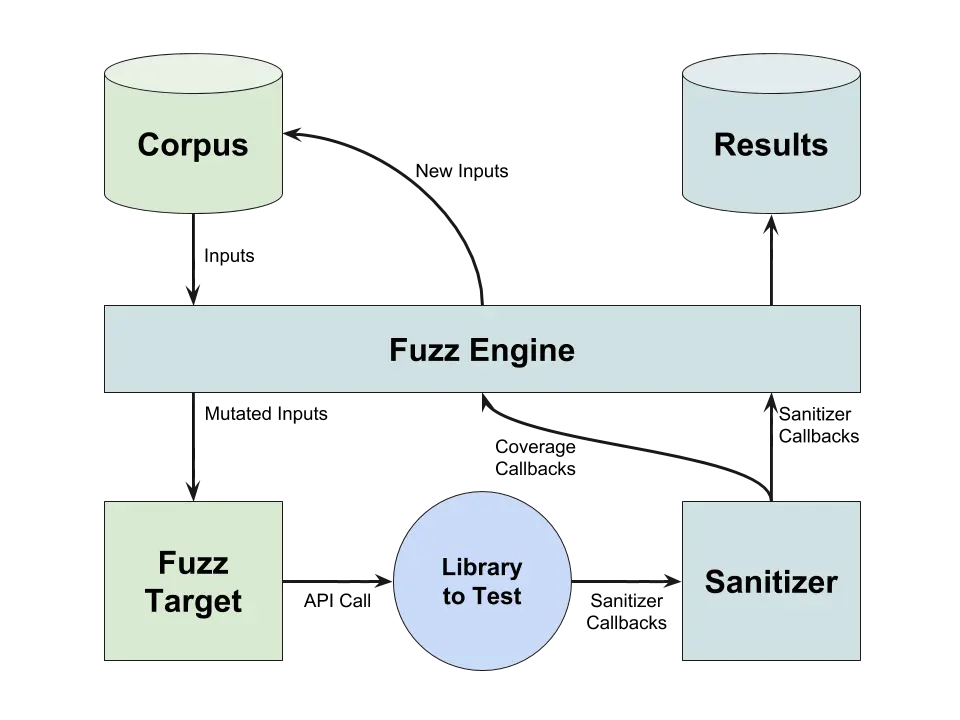
An interesting extension of greybox fuzzers is the ability to direct the search to a specific point in the application. This approach is called "Directed Greybox Fuzzing." This type of fuzzing can be used to direct searches to newly added code or to critical parts of the code.
Dictionaries are of interest for all types of fuzzers. They define sequences that are known to occur frequently in the input (for example, magic numbers). Fuzzers will use them when generating input, which can make it converge faster.
Evolutionary fuzzing is based on genetic algorithms. Inputs typically go through a cycle:
- evaluation of test inputs,
- removing low-ranking inputs,
- mutation: small changes in the remaining inputs,
- a combination of well-ranked inputs
Whitebox fuzzing generates inputs based on static program analysis, primarily based on branching conditions. The branching conditions are examined by symbolic execution, and the inputs are targeted at specific new code branches. This makes it efficient, as it allows for exploring large parts of the code, but the problem is that solving the constraints is very slow. An example of a whitebox fuzzer is SAGE.
Code instrumentation
The fuzzing engine detects an error by crashing the tested application. However, a significant portion of the bugs do not cause the application to crash, the crash necessitates a specific combination of multiple bugs, or the crash is not reproducible. This problem is solved by code instrumentation. By using instrumentation, some bugs in implementation become easier to detect and reproduce.
Instrumenting the binary code of the application under test introduces checks such as heap and stack memory allocation bounds being exceeded, the use of uninitialized memory, dereference of the NULL pointer, or the existence of undefined behavior (such as integer overflow). These checks are not automatically enabled because they have a significant impact on program speed (about half the performance). Checks are inserted into instrumented code by replacing functions like malloc and free and inserting canaries at field boundaries. A custom memory allocator can therefore cause the fuzzing to reveal fewer errors.
The application can be run in a virtual machine for better insight into the state of its execution. In the case of interpreted languages, this is the default option.
Higher-level instrumentation can detect bugs of a different nature than memory handling. It can compare documentation with measured reality; for example, it can take into account documented crash conditions or verify the temporal complexity of a function. For example, fuzzing can detect the Log4Shell ACE vulnerability in the Log4J logging framework. An example is SystemSan, a tool aimed at finding bugs caused by executing shell commands.
Fuzzer can also examine the output of the system and determine if it is expected or contains anomalies. To do this, the fuzzer needs information about the output, which can be provided by the corpus. Heuristics can be applied to the output to look for signs of vulnerabilities, such as XSS. The advantage is that no access to the source code is required (blackbox testing). On the other hand, deploying such a system is more laborious.
Fuzzing by Microsoft Security Development Lifecycle
The Microsoft Security Development Lifecycle (SDL) dedicates a chapter to fuzz testing. Fuzzing is said to focus on file parsers, network protocol parsers, and other APIs. The system is considered passable if no crashes occur during 100,000 iterations of fuzzing, assuming the fuzzer generates good data that covers a large portion of the paths in the code.
The book makes specific suggestions for which inputs should be tried. Attention should also be focused on memory consumption, which may indicate memory leaks.
Fuzzer comparison
A good metric for comparing fuzzers is the average code coverage achieved in a defined period of time, which shows a strong correlation with the number of bugs found. Alternatively, the initial coverage rate may be of interest.
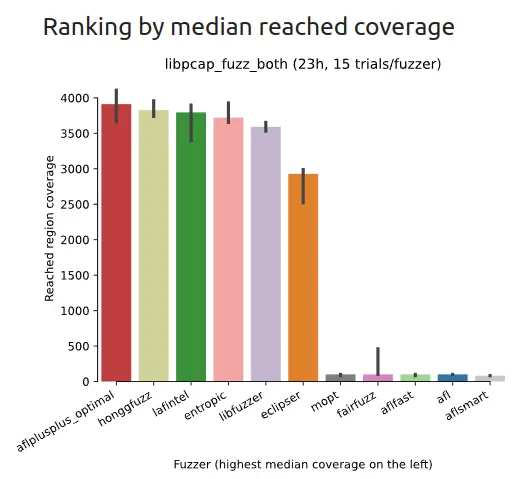
Which fuzzers to include in the testing process is an individual decision. Each fuzzer will better cover different types of applications. Helpful here may be FuzzBench, which compares fuzzers on different types of applications. Examples of comparisons are shown in Figure 2.
Some well-known fuzzers include AFL, Hongfuzz, Entropic, Radamsa, and libFuzzer. Next, libFuzzer will be examined in more detail.
LibFuzzer
LibFuzzer is part of the LLVM project and is integrated into the Clang compiler. No additional installation is required to use it, so it is ideally suited as an entry point into the world of fuzzing.
It is primarily designed for fuzzing libraries. When the -fsanitize=fuzzer,address compiler flag is used, LLVM includes code instrumentation (ASan, UBSan, MemorySanitizer, and others). It may be important to add instrumentation to the target application's dependencies as well.
The function, as shown in the figure below, is the entry point to the fuzz target. Its parameter is an array of bytes in the form of a pointer and length. At compile time, an executable is generated that calls this function. The fuzz target is portable across fuzzers; using multiple fuzzers is even recommended.
fuzz_target.cc
1extern "C" int LLVMFuzzerTestOneInput(const uint8_t *Data, size_t Size) {2 DoSomethingInterestingWithMyAPI(Data, Size);3 return 0; // Values other than 0 and -1 are reserved for future use.4}5
LibFuzzer falls into the category of coverage-guided fuzzers, and as such, it maintains a corpus of inputs. The corpus is stored in a directory where a single file represents one input. The file is named with the input hash for easy retrieval from the logs.
LibFuzzer has a merge function for the purpose of minimizing the corpus. The merge preserves a minimum set of inputs such that the original coverage is maintained.
The output of the fuzzer when the library crashes may look like the code sample below. The binary input has been written to the ./crash-[hash] file.
fuzzer log
1==210935==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x629000009748 at pc 0x555d20892077 bp 0x7fff7aa11390 sp 0x7fff7aa10b602READ of size 58371 at 0x629000009748 thread T03# 0 0x555d20892076 in __asan_memcpy(/ mnt / data / projects / sco / example2 / handshake - fuzzer + 0x2ab076)(BuildId : dd42969bf1eb4fff6bac63b54d6ebb170f688159)4# 1 0x555d208df785 in tls1_process_heartbeat / mnt / data / projects / sco / example2 / openssl - 1.0.1f / ssl / t1_lib.c : 2586 : 356[zbytek stack trace vynechan pro strucnost]78handshake - fuzzer + 0x1f3d14)(BuildId : dd42969bf1eb4fff6bac63b54d6ebb170f688159)910Test unit written to ./crash-c5f56acd0537240850686a0bee5db97ad67d6b3111
Following the collection of suspicious inputs, the maintainer arrives and manually replicates the crash from the logs, evaluates the cause of the crash and fixes it as needed.
Fuzzing on the cloud
An interesting use case is long-term fuzzing on cloud servers. ClusterFuzz is a fuzzing infrastructure developed by Google.
Fuzzing is automated and can be highly parallel (thousands of instances). The infrastructure downloads current versions of integrated projects from their repositories, compiles them (many languages are supported), and fuzzes them using many compatible fuzzers. It minimizes the input and creates a report about it in collaboration tools. It keeps the inputs for bugfix verification and regression testing. ClusterFuzz can also be run locally.
Distributing jobs makes it more difficult to maintain a global corpus; it also needs to deduplicate findings and cluster similar application crashes.
Alternatively, fuzzing can be run as part of a CI service, similar to other tests, each time a pull request is made to GitHub. Regression is a common source of bugs, and infrastructure should automatically detect this before releasing a public version. Part of the configuration is the fuzzing time. If a crash occurs within a predetermined time window and the application does not crash, the CI phase will pass. Fuzzing should not slow CI down too much; ideally, it should run in parallel with other tests. CIFuzz is an example of such a tool.
Fuzzing open source software (OSS)
All digital infrastructure depends on open-source projects. A single vulnerability in a widely used library can have a major impact.
The OSS-Fuzz project performs continuous fuzzing using the infrastructure ClusterFuzz on more than 550 open source projects, where it has uncovered more than 36,000 bugs. Integration of open-source software into OSS-Fuzz is supported financially. The disclosure of discovered issues is governed by rules.
GUI Fuzzing
An interesting case of fuzzing is the fuzzing of GUI inputs. Instead of a sequence of bytes, sequences of user events are generated. This presents difficulties because the search space is orders of magnitude larger.
For testing Android OS applications, there is a tool called The Monkey, which is built into the Android Studio development environment. The tested application is run in an emulator with randomly generated user inputs. In the event of an exception being raised, the application crashes or freezes, and a report is generated.
The Sapienz tool improves this approach with more intelligent searching and by finding shorter sequences leading up to a crash, making it much easier for the practicality of debugging.
Fuzzing achievements
To demonstrate, I'll list two real-world critical bugs discovered through fuzzing.
Heartbleed
Heartbleed is a buffer over-read vulnerability in the TLS implementation of the OpenSSL cryptographic library (versions 1.0.1 to 1.0.1f) that allows an attacker to read memory and steal sensitive information, such as cryptographic keys. The vulnerability has been assigned CVE number CVE-2014-0160.
The vulnerability was discovered independently by Google and Codenomicon in 2014. Codenomicon discovered it with its fuzzing tool.
The core of the vulnerability lies in a missing bounds check before reading from memory. The length parameter is taken from user input (the packet) and is not properly handled. The buffer over-read bug category does not typically cause a crash and is therefore detectable only with instrumentation such as ASan mentioned earlier. Alternatively, it can be detected by examining the library output.
An attacker sends a short TLS heartbeat packet, which is used to keep the connection open. The contents of the packet are a sequence of bytes and their length. If the length given is greater than the actual length of the sequence, the contents of memory after the buffer is sent back in the packet. The relevant code is attached in figure below.
1n2s(p, payload); // payload includes length2pl = p; // pl is a pointer to buffer34// ... more code56// memcpy(dest, src, n)7memcpy(bp, pl, payload); // payload is controlled by attacker
The fix for the bug was straightforward: adding a simple bounds check by comparing the total packet length and the declared message length.
TinyGLTF command injection
CVE-2022-3008 is a command injection vulnerability in the library for TinyGLTF 3D model transport. The flaw was discovered using OSS-Fuzz.
A wordexp function path expansion causes the vulnerability when parsing a .gltf file. See anexample of the vulnerability:
Shell session
1$ cd tinygltf && make all2$ echo '{"images":[{"uri":"a`echo iamhere > poc`"}], "asset":{"version":""}}' > payload.gltf3$ ./loader_example payload.gltf4$ cat poc
The bug has been fixed by removing path expansion in files.
Precautions against fuzzing
For security purposes, it may be interesting to introduce features into the software to slow down offensive fuzzing. So-called anti-fuzzing involves efforts to make fuzzing harder. The motivation is to make it more expensive to fuzz and thereby reduce the chance of finding a vulnerability, prolonging the lifetime of the technology.
To detect active fuzzing, we can compare
- the current and expected input frequency,
- the current and anticipated frequency of incorrect inputs,
- the code's current and expected paths.
If fuzzing is detected, we can then deploy several defense behaviors. Examples are false application crashes or misinformation messages in exceptions (for example, reporting a NULL pointer dereference exception regardless of the actual cause of the crash). By reducing performance, we can dramatically reduce the effectiveness of fuzzing. A more passive option is to notify telemetry developers that fuzzing attacks are in progress. False reports are investigated by the attacker, wasting their time and effort. The patience of an attacker is not infinite, and with similar difficulties, he will sooner decide to target another, easier target.
It also depends on the software deployment. If the software is publicly distributed, it must be assumed that the attacker has knowledge of its internal architecture. He will be able to modify the software and eliminate the measures with some effort.
However, if the software is deployed privately and the attacker's only option is to fuzz through the network, the chances of defense are much better. The simplest solution, once fuzzing is identified, is to block or restrict the attacker's traffic speed. Alternatively, we can introduce noise in the form of false errors once fuzzing is detected.
The risk of these measures is causing problems for real users. If fuzzing detection results in false positives, it will negatively affect the reliability of the software. Software technical support can be unnecessarily burdened with reports of problems caused by the measures and may result in financial loss to the company. Another problem may be the difficulty of software development, for example, in replicating reported bugs.
Therefore, it may be critical to decouple the implementation of these measures so that they can be removed in internal versions of the software or simply removed altogether.
Anti-fuzzing is essentially hiding bugs, which is a less appealing solution than writing safer code, but it has its uses. This concept is related to the concept of "anti-tamper software," which is a type of software that, through methods such as obfuscation and runtime monitoring, makes it harder for software modification by an attacker.
Other uses of fuzzing
For the sake of interest, here are other, less traditional uses of fuzzing:
- Differential fuzzing: when there are two different implementations for the problem, they can both be fuzzed on the same inputs and tested for correctness by comparing the outputs. A different result indicates a bug in one of the implementations. This is typically how parser implementations, as well as compilers and cryptographic libraries, can be tested.
- Hardware fuzzing: hardware can be fuzzed directly, or it can be fuzzed through the synthesis on the FPGA, or through software simulation (in the form of Verilog compiled into C++ with a test harness).
Conclusion
Fuzzing, in its simplest form, is an inexpensive test implementation technique that can expose many vulnerabilities in your application. It is worth using it in the early stages of development to complement other tests. It is always possible to return to your fuzzing implementation afterwards and improve it. The fuzzing infrastructure should be designed so that multiple fuzzers can be used easily.
According to publicly observed rankings alone, fuzzing has found tens of thousands of bugs. This shows its great relevance. Nevertheless, fuzzing is just one of a number of tools that should be part of a project's testing.